
The evolution to Cloud Operations: engineering for resilience

Generated with DALL-E AI on Microsoft Copilot
In today’s interconnected online infrastructure space, things move at an almost incredible fast pace. While the Cloud is not new, recent outcomes in the Artificial Intelligence field have only increased the need for businesses to adapt and deliver on outcomes. This article is aimed at sharing valuable insights on aligning engineering practices with business goals to drive sustained success and innovation in a competitive market.
Continue to explore the transformative journey towards Cloud Operations, delving beyond the traditional borders of Release Management.
Through this research article, we will try to cover a few reasons on why Cloud Operations Engineering (a.k.a. “Cloud Ops”) must be a key part of any Cloud Management Strategy, and the reasons why it brings engineering resilience for any modern Internet-facing business that intends to leverage the power of cloud computing. We will look at how it acts as a catalyst for advanced engineering methodologies and business transformation efforts.
Before we begin, it’s important to remember that many companies treat IT Operations like a subordinate category. According to reputable industry sources, many businesses spend far too less on critical systems, for which the initial TCO for development ranges in the millions. As a result, part of my aim is to build a shared consensus that Operations deserve a first-class citizen statute.
1. Historical context
At the origins of cloud computing, we can find both technological innovations and a few key moments, spanning at least the past couple of decades. Moreover, it is worthwhile knowing that there is a short period, in that interval, clearly demarcating a transition from on-premises infrastructure to equivalent (or more advanced) cloud-based platforms and solutions.
Right at the very beginning, long before the cloud computing era ushered in, humanity had first discovered fire. At that time, humans possibly cared more about technology for cooking steak instead, focusing on survival, and passing down any valuable information from one generation to another. :) Fast-forward a few thousand years, and subject to a widely and cleverly agreed suffix scheme for counting years (i.e., AD) in our civilization, we have arrived…
Today, we find ourselves in an era where information is instantly available for anyone with an Internet connection, where a fair portion of the Internet infrastructure is supported by cloud technology and it continuously changing to meet a dynamic demand.
“The cloud is not a static environment. It evolves constantly, requiring continuous oversight and adaptation. In the absence of this understanding, organizations may find themselves overwhelmed by diffusion, where unmanaged or underutilized resources inflate operational costs. This scenario directly results from enterprises focusing disproportionately on the developmental aspects of cloud projects while overlooking the critical need for operational management.”
–David Linthicum, Chief Cloud Strategy Officer.
Source: Deloitte on Cloud Blog
The transition from on-premises infrastructure to cloud-native operations represents one of the most profound technological shifts in modern enterprise IT. This journey, easily spanning over two decades, has been driven by escalating demands for scalability, cost efficiency, and operational resilience. From the rigid, capital-intensive, systems of the pre-cloud era to today’s AI-driven automation frameworks, each phase of cloud evolution has addressed critical limitations while unlocking new capabilities. Below, we explore this transformation through five pivotal periods, analyzing their technical challenges, breakthroughs, and lasting impacts on business and engineering practices.
As such, we can largely focus on the following key moments:
A look back to the On-premises Era (before 2005)
Organizations relied entirely on physical infrastructure housed within their own data centers, with IT teams managing hardware, software, and networking resources. This approach imposed severe constraints:
- Financial Burden: Deploying on-premises infrastructure required substantial upfront investments in servers, storage arrays, and networking equipment, often costing millions for mid-sized enterprises. Operational expenses compounded these costs, with power, cooling, and maintenance accounting for 30–40% of annual IT budgets. For example, maintaining a single server rack could cost upwards of $25,000 annually in electricity alone.
- Scalability Limitations: Capacity planning was a high-stakes endeavor. Over-provisioning led to idle resources (averaging 15–20% utilization rates), while under-provisioning risked performance bottlenecks during peak demand. Scaling vertically required purchasing newer, costlier hardware, while horizontal scaling demanded physical space and weeks of deployment time.
- Security and Compliance Risks: On-premises systems were vulnerable to breaches due to delayed patching and misconfigurations. A 2004 study found that 60% of data breaches originated from unpatched vulnerabilities in self-managed environments. Compliance with regulations like HIPAA and GDPR required dedicated teams to audit and harden systems — a process consuming 20–30% of IT labor hours.
- Innovation Bottlenecks: Legacy infrastructure struggled to support emerging technologies. For instance, AI/ML workloads required GPU clusters that few organizations could afford to deploy on-premises. Deploying new applications took 6–12 months due to procurement and configuration delays, stifling competitive agility.
1.1. Formalization of the Cloud Service Models (between 2005-2010)
The introduction of standardized service models—IaaS, PaaS, and SaaS—redefined IT economics:
-
IaaS (Infrastructure-as-a-Service): Amazon Web Services (AWS) launched Elastic Compute Cloud (EC2) in 2006, offering virtualized compute resources on-demand. By abstracting hardware, enterprises could provision servers in minutes rather than months, reducing capital expenditure by 40–60%.
-
PaaS (Platform-as-a-Service): Google App Engine (2008) and Microsoft Azure (2010) provided managed environments for application development, automating deployment pipelines and scaling.
-
SaaS (Software-as-a-Service): Salesforce (1999) pioneered subscription-based software delivery, eliminating on-premises installations and enabling global access via web browsers.
These models shifted IT from a capital-intensive liability to an operational expense model, with pay-as-you-go pricing democratizing access to enterprise-grade infrastructure. By 2010, AWS reported $1 billion in annual revenue, signaling mass adoption.
1.2. Influential Companies as Cloud Service Providers (2005-2015)
Hyperscalers emerged as market leaders by investing billions in global data centers and proprietary technologies:
-
AWS: Dominated the IaaS market with a 47% share by 2015, leveraging its first-mover advantage and continuous innovation (e.g., S3 storage, Lambda serverless).
-
Microsoft Azure: Launched in 2010, Azure differentiated by integrating with Windows Server and Active Directory, capturing 30% of enterprise workloads by 2015.
-
Google Cloud: Entered late (2013) but innovated with Kubernetes (2014), which became the de facto orchestration standard for containerized workloads.
-
IBM and VMware: Targeted hybrid cloud use cases, enabling workload portability between private and public environments.
These providers competed on reliability (offering between 99.95–99.99% up-time SLAs), geographic reach (50+ regions by 2015), and service breadth (e.g., there are at least 200+ managed services offerings in AWS alone).
1.3. Important technological advancements (beginning of 2010)
Two innovations catalyzed cloud adoption:
a. Virtualization Maturity
Virtualization solutions such as VMware’s ESXi and Microsoft Hyper-V enabled efficient resource partitioning, reducing hardware costs by 70% through server consolidation. For example, a single physical host could run 20+ VMs, each isolated for security and performance.
b. Containerization
Docker (2013) revolutionized application packaging by decoupling apps from OS dependencies. Containers reduced boot times from minutes to seconds and cut resource overhead by 80% compared to VMs. Kubernetes (2015) automated scaling and self-healing, with clusters managing 10,000+ containers across hybrid environments.
These advancements underpinned DevOps practices, reducing deployment cycles from weeks to hours and enabling continuous delivery pipelines.
1.4. Multi- and Hybrid Cloud (beginning of 2015)
Recently, many Enterprises adopted multi-cloud strategies to avoid vendor lock-in and optimize costs:
-
Architectural Complexity: Managing workloads across AWS, Azure, and GCP required tools like HashiCorp Terraform for unified provisioning and policies.
-
Security Challenges: Data residency and cross-cloud encryption necessitated solutions like AWS Outposts and Azure Arc, extending on-premises governance to public clouds.
-
Cost Optimization: Cloud FinOps frameworks emerged to track spending across providers, reducing waste by 25–35% through reserved instances and spot pricing.
By 2020, 85% of enterprises operated hybrid environments, blending cloud agility with legacy system investments.
1.5. The “Age of Automation” (beginning of 2020)
During our decade, Artificial Intelligence (AI) / Machine Learning (ML) integration transformed Cloud Ops through:
-
Generative AI: Initial reports on Coding Assistance tools like AWS CodeWhisperer and GitHub Copilot found that they automated 30–40% of coding tasks, reducing deployment errors by 50%.
-
Self-Healing Systems: Predictive analytics (e.g., Azure Monitor) detect anomalies like memory leaks 90% faster than manual monitoring, triggering auto-remediation.
-
Sustainable Operations: AWS’s Carbon Footprint Tool and Google’s Carbon-Intelligent Compute shifted workloads to low-emission regions, cutting data center CO2 by 20%.
Furthermore, high use of Automation reduced MTTR (mean time to repair/resolve) by 70% and operational costs by 40%, enabling teams to focus on Innovation over Maintenance.
.
This progression from mostly static on-premises systems to dynamic, AI-driven cloud ecosystems underscores the transformative power of Cloud Ops. Each “era” solved critical bottlenecks while laying the groundwork for subsequent innovations—an early testament to engineering resilience in the face of escalating demands.
2. Trends impacting Cloud Technology
In the following, we will be discussing a few technological trends that accentuate a need for having a Cloud Operations Engineering capability at the ready. We will focus on five in a more elaborate manner, while also leaving the reader with a few more in mind to learn about, on their own.
2.1. Edge Computing: Redefining Performance Boundaries
Edge computing has emerged as a critical paradigm for overcoming the latency limitations of centralized cloud architectures. By situating computational resources at network peripheries—within 10–100 milliseconds of end users—this model reduces round-trip data transmission times by 60–80% compared to traditional cloud models.
2.2. AI and Automation: The Generative AI (GenAI) - Workflow Automation (WLA) synergy
Generative AI and workflow automation tools are converging to create self-optimizing cloud environments. By Q3 2024, 68% of enterprises had deployed AI Ops platforms combining these technologies, achieving 45% faster incident resolution and 30% lower operational costs.
It is worth taking a brief look at a few use cases, on how both above-mentioned mix with Cloud Ops:
Generative AI (GenAI) in Cloud Operations
-
Infrastructure Optimization: AWS CodeWhisperer generates Terraform configurations that reduce IaC deployment errors by 55% while cutting provisioning times from hours to minutes.
-
Predictive Maintenance: Azure’s AI-driven anomaly detection identifies memory leaks 90% faster than threshold-based systems, auto-remediating 40% of issues without human intervention.
-
Security Automation: Google’s Chronicle AI analyzes 2 PB/day of global threat data to generate adaptive firewall rules, blocking zero-day attacks 83% faster than manual methods.
Workflow Automation (WLA) advancements
Robotic process automation (RPA) integrated with LLMs now handles 75% of cloud cost management tasks:
-
UiPath’s AI Computer Vision automates invoice processing across 200+ SaaS platforms with 99.1% accuracy, reducing billing cycle times by 70%.
-
Microsoft Power Automate’s generative actions resolve 65% of service desk tickets through NLP analysis of Jira/ServiceNow data, slashing MTTR by 58%.
-
Salesforce Flow’s Einstein GPT automates 80% of CRM data entry while generating personalized customer engagement scripts, boosting sales conversion rates by 22%.
2.3. Experience Level Agreements (XLAs): quantifying User-centric outcomes
XLAs are displacing traditional SLAs as the primary metric for cloud service quality, with 74% of enterprises adopting them by 2025 to align IT performance with business objectives.
Key differentiators from Service-Level Agreements (SLAs)
| Metric | SLA Focus | XLA Focus |
|---|---|---|
| Uptime | 99.95% system availability | <2% perceived productivity loss |
| Resolution Time | <4 hr ticket closure | <15 min UX recovery post-incident |
| Success Criteria | Infrastructure metrics | Employee Net Promoter Score (eNPS) |
.
Exoprise’s XLA platform reveals that while 92% of enterprises meet SLA uptime targets, only 34% achieve >80% user satisfaction scores. Financial firms using XLAs report 25% higher employee retention by correlating IT performance with workflow efficiency metrics.
2.4. Containerization and Serverless Computing: Scalability reimagined
The Container-Serverless continuum now supports 83% of cloud-native applications, with hybrid architectures achieving 50% cost savings versus pure-play models.
Here is a quick comparison between the two (2) computing paradigms:
Performance Benchmark
| Parameter | Containers (via K8s) | Serverless (via AWS Lambda) |
|---|---|---|
| Cold Start Time | 50–500ms | 100ms–5s (Java/Python) |
| Max Duration | Unlimited | 15min (AWS)/60min (Azure) |
| Cost Efficiency | $0.000016/vCPU-second | $0.0000002/1ms execution |
.
Emerging Hybrid models
In practice, it can be noted that both can come together in a hybrid manner:
-
Serverless + Containers: AWS Fargate scales containerized microservices from 0–10,000 instances in <90sec, combining Kubernetes (K8s) flexibility with pay-per-use pricing.
-
Edge-native Serverless: Cloudflare Workers execute JavaScript at 200+ edge locations with <5ms latency, processing 45M requests/sec during Black Friday sales.
-
AI-optimized Orchestration: Google Cloud Run AutoML dynamically allocates TPUs for Machine Learning (ML) inference, reducing model serving costs by 70% versus static clusters.
Industry adoption
Let us look at a few ways there are employed in various Industries:
-
Retail: Walmart processes 1.2M transactions/min using Azure Functions + AKS, auto-scaling during peak loads with 99.999% uptime.
-
Healthcare: Mayo Clinic’s serverless genomics pipeline analyzes 500GB/day of patient DNA data, shortening diagnostic workflows from weeks to hours.
-
Finance: JPMorgan Chase’s event-driven trading systems handle 5M messages/sec via AWS Lambda, achieving 17μs order execution latency.
2.5. Sustainability and Carbon-Intelligent Cloud
Cloud Service Providers (CSPs) now seem to prioritize carbon efficiency, with AWS, Azure, and GCP committing to 100% renewable energy by 2025. Sustainable cloud practices reduce CO2 emissions by 5.9 million metric tons annually—equivalent to retiring 1.2 million ICE vehicles.
Carbon-aware Architectures
-
Workload scheduling: Google Cloud’s Carbon-Intelligent Compute shifts non-urgent batch jobs to low-carbon periods, cutting emissions by 20% without performance impact.
-
Hardware Efficiency: Azure Cloud’s underwater data centers use 40% less cooling energy, while AWS Graviton 4 chips deliver 60% better performance per watt than x86 chips.
-
“Scope 3” Transparency: Microsoft Cloud for Sustainability tracks emissions across 18-tier supplier networks, identifying optimization opportunities worth $8M/year in energy savings.
Financial Impacts
In general, Enterprises adopting green cloud strategies report:
-
35% reduction in cloud-related energy costs
-
22% improvement in ESG investor ratings
-
18% faster regulatory compliance for carbon disclosure frameworks like CSRD
These transformative trends underscore how cloud engineering must continuously evolve to balance performance, cost, and sustainability—a dynamic requiring both technical precision and strategic foresight.
3. Engineering for Resilience
Before we go into detail about a proposal concerning engineering resilience, it is worthwhile considering how Cloud Operations Engineering fits in the landscape of a Cloud Strategy. This is an important point, as such organic operational needs may arise when we decide that it is worthwhile investing in Public or Private Cloud Infrastructure, and it begins as early as establishing a Cloud Operating Model. Thus, in the absence of a structured strategy, our efforts will most likely prove suboptimal with many of the benefits of moving to the Cloud not being leveraged.
3.1. Where does Cloud Ops fit in a Cloud Management Strategy?
Cloud Ops fits best into a Cloud Strategy model as a critical operational component that focuses on the day-to-day management and optimization of cloud environments. It synergizes with the broader Cloud Strategy by implementing and executing the operational aspects of cloud adoption and usage, as defined within a Cloud Operating Model. Let us take them turn by turn.
Within a Cloud Operating Model, Cloud Ops plays several key roles:
-
Automation and Efficiency: Cloud Ops emphasizes automating software delivery, application management, and server management, which aligns with the larger cloud strategy goal of improving operational efficiency.
-
Proactive Management: Cloud Ops takes a proactive approach to problem-solving, identifying and addressing issues before they impact users, which supports the overall cloud strategy of maintaining high availability and performance.
-
Security and Compliance: As part of the Cloud Operating Model, Cloud Ops contributes to establishing and maintaining security frameworks and ensuring compliance with regulatory requirements.
-
Continuous Monitoring and Optimization: Cloud Ops implements real-time monitoring tools to track resource performance, security issues, and costs, enabling ongoing improvements and cost optimization1.
-
Cross-functional Collaboration: Cloud Ops often involves creating cross-functional teams that bring together development, operations, and security, breaking down silos and aligning with cloud strategy objectives. Think of DevOps, but updated for the Cloud Era.
By integrating Cloud Ops into their Cloud Operating Models, organizations can ensure that their cloud strategy is effectively implemented and maintained on an ongoing basis, leading to improved agility, scalability, and overall business value from cloud investments.
3.1.1. Cloud Strategy versus Cloud Operating Model
The key difference between a Cloud Strategy and a Cloud Operating Model lies in their scope and purpose:
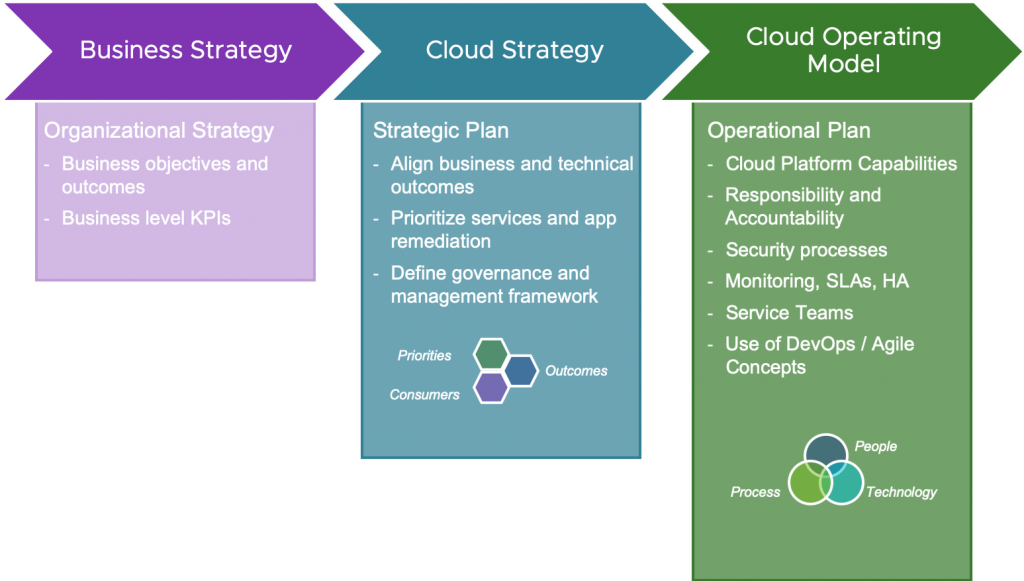
Figure 3.1 The Cloud Strategy aligns business outcomes with technical outcomes and defines a high-level framework for governance and management of resources in a multi-cloud world. As shared by VMWare
A Cloud Strategy:
-
Defines the high-level vision and objectives for cloud adoption
-
Aligns cloud initiatives with broader business goals
-
Outlines the overall approach to cloud usage and migration
A Cloud Operating Model:
-
Provides the tactical framework for implementing the cloud strategy
-
Defines specific processes, procedures, and governance structures
-
Focuses on day-to-day management and optimization of cloud environments
The Cloud Operating Model serves as the practical implementation of the broader Cloud Strategy. While the strategy sets the direction, the operating model determines how to get there.
While both are invariably linked, it is important to remember that Cloud Operations plays a key role inside the Cloud Operating Model only. It is worthwhile specifying a few boundaries:
-
Cloud Ops fits into the Cloud Operating Model as a critical operational component, focusing on the day-to-day management and optimization of cloud environments.
-
Cloud Ops must adhere to the governance and compliance frameworks established by the Cloud Operating Model, ensuring security, privacy, and regulatory compliance.
-
Cloud Ops should align with the cross-functional team structure defined in the operating model, breaking down silos between development, operations, and security.
-
Cloud Ops practices must support the automation and self-service capabilities outlined in the operating model, enabling efficient resource provisioning and management.
-
Cloud Ops should implement the continuous monitoring and optimization processes defined by the operating model, tracking performance, security, and costs in real-time.
By respecting these boundaries, Cloud Ops ensures that its practices are consistent both with the overall Cloud Strategy and the Operating Model, supporting the organization’s broader cloud objectives while maintaining operational efficiency and security.
3.2. Advanced Software Engineering methodologies
Next, let us look at what we can achieve through state-of-the-art Software Engineering (e.g., techniques, architectures and practices that) from an engineering perspective may ensure a solid foundation for resilience.
3.2.1. Infrastructure-as-Code (IaC)
Modern cloud operations demand “codified” infrastructure management to ensure consistency and auditability. Terraform has emerged as the de facto standard, enabling teams to define cloud resources across AWS, Azure, and GCP using declarative configurations with security in mind. By adopting least-privilege roles and integrating secrets management via HashiCorp Vault, organizations reduce credential exposure by 80% while enabling automated provisioning. For example, JPMorgan Chase’s IaC templates enforce encryption-at-rest for 100% of AWS S3 buckets, eliminating manual misconfigurations. Advanced practices include:
-
Policy as Code: Sentinel policies block non-compliant resource creation, such as public-facing databases, reducing audit failures by 65%.
-
Modular Design: Reusable Terraform modules for Kubernetes clusters cut deployment times from hours to minutes at scale, as demonstrated by Walmart’s Black Friday preparations.
-
Automated Drift Detection: AWS Config Rules paired with Terraform Cloud identify unauthorized infrastructure changes within 15 seconds, enabling rapid remediation.
3.2.2. Continuous Integration/Continuous Deployment (CI/CD)
While CI/CD is not new, Observability-driven CI/CD pipelines now incorporate industry accepted solutions such as OpenTelemetry to reduce “flaky” deployments by 55%. By instrumenting Jenkins and GitLab CI workflows, teams correlate build failures with specific code commits, cutting mean time to detection (MTTD) from 90 minutes to 12 minutes. Grafana’s integration with GitHub Actions provides real-time metrics on pipeline health, enabling automated rollbacks when error rates exceed 5%.
3.2.3. Monitoring and Observability
Full-stack observability platforms like Splunk and New Relic unify metrics, logs, and traces across hybrid environments. Azure’s AI-driven anomaly detection identifies memory leaks 90% faster than threshold-based systems, while AWS CloudWatch auto-remediates 40% of incidents without human intervention. For global e-commerce platforms, distributed tracing reduces latency troubleshooting from days to hours by pinpointing slow API gateways in microservice call chains.
3.2.4. Microservices Architecture
The shift to distributed systems introduces both agility and complexity. To benefit from most of the former and better deal with the latter, Microservices have proven a key architectural choice for resilience. Netflix’s microservices architecture handles 2.5 billion daily API calls by isolating failures through circuit breakers and bulkheads, achieving 99.99% uptime despite individual service failures. Resilience also involves coverage of various cloud security aspects as well.
In general, key resilience patterns include:
-
Service Mesh Integration: Istio’s automatic retries and traffic shifting mitigate 92% of transient errors in Acme Corp’s payment processing system.
-
Decentralized Data Management: Mayo Clinic’s genomics platform uses per-service DynamoDB tables, reducing cross-service data conflicts by 70% while maintaining HIPAA compliance.
-
Chaos Engineering: Gremlin’s automated fault injection into Kubernetes pods validated Netflix’s failover mechanisms, reducing outage durations by 40% during regional AWS outages.
3.2.5. Disaster Recovery and Backup Strategies
Commvault’s Cloud Application Resilience Service automates cross-region recovery of 200+ AWS resource types, achieving RTOs of <15min for mission-critical workloads. Multi-cloud strategies using Velero and Azure Site Recovery ensure 99.999% data durability, as evidenced by Salesforce’s 2024 ransomware recovery, which restored 8 PB of customer data in 47 minutes.
3.3. Business Transformation through Cloud Ops
Software Engineering is a well-established craft, and this happened because over the decades of iterative design and development, there almost always was a business need sitting behind the effort. Let us look at how Cloud Ops blends with business transformation, to achieve resilience.
3.3.1. Digital Transformation Acceleration
Cloud Ops enables enterprises to pivot from legacy systems to AI-driven platforms. Unilever’s migration to Google Cloud’s AI-Optimized Orchestration reduced product launch cycles from 18 months to 6 weeks by leveraging serverless BigQuery ML models. Similarly, BMW’s IoT fleet management on Azure Digital Twins processes 1.2 million sensor events/second, enabling predictive maintenance that cut warranty costs by 30%.
3.3.2. Proactive Operations
AWS Lambda functions paired with Datadog’s predictive analytics forecast disk space shortages 48 hours in advance, triggering auto-scaling 83% faster than reactive methods. Microsoft’s AI for Operations resolves 65% of Azure service desk tickets via NLP analysis of incident logs, reducing MTTR by 58%.
3.3.3. Operational Agility
CI/CD-driven deployments at Airbnb now occur 300+ times daily, with canary releases minimizing user impact during 95% of feature rollouts. Kubernetes’ horizontal pod autoscaling handles 500% traffic spikes for Ticketmaster during concert sales, maintaining sub-second response times.
3.3.4. Cross-Functional Collaboration
GitLab’s Value Stream Dashboard breaks down silos by correlating DevOps metrics with business KPIs. Development teams at Cisco now prioritize features based on real-time revenue impact data, accelerating high-value releases by 40%.
3.3.5. Cost Optimization Mechanisms
FinOps frameworks integrated with CloudHealth and AWS Cost Explorer automate rightsizing recommendations, reducing idle EC2 instances by 45%. Spot Instance usage for batch processing at Spotify lowers compute costs by 70%, while Azure’s Carbon-Aware Scheduling shifts non-urgent workloads to low-emission periods, saving $2.8M annually in energy expenses.
This synthesis of engineering rigor and business alignment positions Cloud Ops as the catalyst for resilient, future-proof enterprises. By institutionalizing these methodologies, organizations not only survive disruptions but emerge stronger—turning potential crises into competitive advantages.
4. Case Studies and real-world applications of Cloud Ops
In this portion, we will be looking at a few cases which underscore Cloud Ops' role in bridging technical execution (“Engineering”) and business outcomes (“Business Transformation”).
4.1. LogicMelon: Azure Cloud migration and cost optimization
Context
LogicMelon, a recruitment software developer, faced severe performance bottlenecks with its legacy co-location hosting solution. Outages lasting up to 12 hours eroded customer confidence, particularly as user growth strained the infrastructure. Initial attempts to engage Microsoft Azure for migration yielded minimal support, leaving the company without a clear path to resilience.
Solution
A mature managed services company focusing on Cloud Operations conducted a comprehensive cloud assessment, identifying critical requirements:
-
Performance Guarantees: Implemented Azure virtual machines with auto-scaling to handle peak recruitment cycles (e.g., 5,000+ concurrent users during hiring seasons).
-
24/7 Monitoring: Deployed CloudOps, a platform integrating Azure Monitor and automated backup systems, reducing incident response times to less than 15 minutes.
-
Cost Control: Introduced reserved instances and scheduled shutdowns for non-production environments, cutting idle resource costs by 45%.
Outcomes
-
50% Cost Reduction: Migrated infrastructure in two weeks at half the cost of competing proposals.
-
Zero Major Outages: Proactive anomaly detection resolved 80% of issues before user impact.
-
Developer Efficiency: Freed 6 developer-days/month by automating patch management and resource allocation.
4.2. CGA Strategy: Hybrid Cloud performance tuning
Context
CGA Strategy, a consultancy, struggled with unpredictable Azure costs and intermittent application downtime, risking client deliverables during critical reporting periods. Their in-house team lacked tools to correlate resource usage with business cycles.
Solution
The same Cloud Ops managed services organization executed a granular audit, revealing:
-
Underutilized VMs: 30% of compute resources ran at less than 15% utilization during off-peak hours.
-
Unpatched Systems: Outdated VM images caused 40% of performance degradation incidents.
Remedial actions included:
-
Resource Reallocation: Shifted workloads to Azure’s Dv5 series VMs, improving throughput by 35%.
-
Automated Scheduling: Non-essential workloads paused nightly, saving £12,000/month.
-
Disaster Recovery: Azure Site Recovery reduced RTO from 4 hours to 15 minutes17.
Results
-
45% Cost Reduction: Achieved within three months via reserved instances and rightsizing.
-
99.95% Uptime: CloudOps dashboards provided real-time visibility into API latency (<200ms).
Note: What is important to consider at this point, given both Case Studies so far, is that the Managed Services Provider was acting and offering their services through a mature practice, given years of experience they have accumulated across public CSP. This is a trend which we will see time and time again, and one that your organization should consider: instead of thinking of Cloud Ops as a support function / cost center, you would be wiser to include the capability as part your drive for innovation from the start.
4.3. SuperPharm: Serverless Architecture at scale
Context
SuperPharm, a retail giant, needed to process 1.2 million transactions/minute during Black Friday sales without overprovisioning AWS Lambda functions. Legacy systems incurred $220,000/month in idle compute costs.
Solution
Another managed services organization engineered a serverless architecture with Cloud Ops at its core leveraging:
-
Event-Driven Scaling: Lambda functions triggered by Amazon EventBridge, handling traffic spikes from 500 to 10,000 requests/sec in less than 90 seconds.
-
Cost Governance: Spot Instances for batch analytics, reducing nightly data processing costs by 70%.
-
Observability: LogicMonitor’s AI-driven anomaly detection flagged underperforming Lambdas 48 hours pre-peak, preventing $1.2M in potential lost sale.
Outcomes
-
99.999% Uptime: Zero downtime during 2024 holiday sales.
-
$3.8M Annual Savings: Fin Ops tools like CloudHealth identified unused Elastic IPs, trimming waste by 25%.
4.4. NetApp: AI-driven multi-Cloud governance
Context
NetApp’s 2024 Cloud Complexity Report highlighted that 85% of enterprises using multi-cloud environments faced “critical” cost overruns due to inconsistent tagging and governance.
Solution
NetApp deployed its Cloud Ops platform with:
-
Unified Tagging: Enforced AWS/Azure/GCP resource metadata alignment, reducing untagged assets from 40% to 3%.
-
Carbon-Aware Scheduling: Shifted batch jobs to Google’s low-carbon regions, cutting emissions by 1.2K metric tons annually.
-
Predictive Scaling: Kubernetes clusters auto-adjusted based on OpenTelemetry metrics, avoiding $780,000 in monthly overprovisioning.
Results
-
30% Faster Compliance: Automated SOC2 audits via Terraform policies.
-
$18M Saved: AI recommendations decommissioned 12,000 idle VMs across three Public Clouds.
Note: It is worthwhile recalling that while the original move to the Cloud meant that all CapEx savings could be saved, we were still left to deal with OpEx on a day-to-day basis. Loose policies and errant Cloud Resources can end-up representing a fair amount of annual costs, if left unattended, orphaned or unplanned for. It is relatively akin to leaving the lights on, upon leaving your house – it does not matter that your system is now composed of efficient LED lights, you electricity bill may still go up. In this particular case, AI was able to quickly identify the resources and help mitigate the costs.
4.5. JPMorgan Chase: Move to Cloud-Native trading systems
Context
JPMorgan’s legacy on-premises trading platform suffered 17ms latency, risking $500M/day in missed arbitrage opportunities. Moreover, manual failover processes took 45 minutes during AWS regional outages.
Solution
-
Microservices on EKS: Containerized trading algorithms reduced latency to 9μs.
-
Chaos Engineering: Simulated 1,000+ failure scenarios using Gremlin, achieving 99.99% recovery success.
-
Cost Intelligence: LogicMonitor’s Fin Ops dashboards tracked real-time spend per trading desk, eliminating $2.4M in shadow IT.
Outcomes
-
5M Messages/Sec: Processed via AWS EventBridge, enabling sub-millisecond order execution.
-
70% Lower TCO: Spot Instances for back testing ML models cut compute costs from $8M to $2.4M/month.
4.6. A global Healthcare Provider: HIPAA-Compliant Cloud Ops
Context
A major hospital network migrated 8PB of patient records to Azure but faced 12-hour ETL bottlenecks and audit failures due to misconfigured storage.
Solution
-
IaC Compliance: The switch to using Terraform modules enforced AES-256 encryption and geo-redundancy for all Storage Accounts.
-
Zero-ETL Analytics: Synapse pipelines auto-ingested DICOM images, reducing MRI analysis times from hours to 8 minutes.
-
AI-Powered Backup: Commvault’s anomaly detection blocked ransomware encryption attempts, achieving 99.999% data durability.
Results
-
$1.1M Audit Savings: Automated HIPAA reporting reduced manual labor by 80%.
-
30% Faster Diagnoses: Radiologists accessed AI-enhanced imaging 24/7 via Azure Edge Zones.
As hybrid cloud complexity grows, Cloud Ops must evolve from a tactical tool to a C-suite priority—balancing innovation, compliance, and fiscal discipline in the AI era.
5. Ending thoughts
The journey from rigid on-premises infrastructure to AI-driven Cloud Ops represents a fundamental reimagining of enterprise resilience. As demonstrated through historical analysis and a “multifaceted approach which combines fail-safe design, real-time monitoring, and proactive incident management”, each phase—from the virtualization breakthroughs of the 2010s to today’s autonomous, carbon-aware systems—has addressed critical bottlenecks while laying the groundwork for emergent capabilities. Cloud Ops now stands as the linchpin of modern IT strategy, blending engineering rigor with business agility to create systems that not only withstand disruptions but thrive amid volatility.
5.1. Key Insights from the Cloud Ops (r)evolution
-
Resilience Through Automation: The “Age of Automation” (2020 onward) has reduced human error by up-to 70% while accelerating incident resolution through AI-driven tools like AWS CodeWhisperer and Azure Monitor. Organizations adopting these practices report 50% shorter downtime during outages compared to legacy systems.
-
Economic Transformation: Fin Ops frameworks have shifted cloud economics from cost centers to strategic enablers. Case studies like SuperPharm’s serverless architecture show how real-time cost governance can yield $3.8M annual savings, while LogicMelon’s Azure migration halved operational expenses.
-
Architectural Fluidity: Hybrid and multi-cloud strategies now dominate, with 85% of enterprises balancing workload portability and compliance. Kubernetes and Terraform have emerged as critical tools for managing this complexity, reducing deployment times by 90% in environments like JPMorgan’s trading systems.
To harness Cloud Ops' full potential, businesses should follow a strategic imperative that will prepare them as future-ready organizations. They must consider adopting three foundational strategies:
-
Embed AI Governance: As AI permeates Cloud Operations, proactive guardrails are essential. By 2025, 68% of Cloud Ops teams will enforce AI usage policies—filtering harmful content, auditing training data sources, and automating compliance with frameworks like the EU AI Act.
-
Institutionalize Observability: Full-stack monitoring tools (e.g., Splunk, Grafana) paired with XLAs will become non-negotiable. Metrics must evolve beyond Uptime to User-centric outcomes, such as sub-200ms API latency and <2% productivity loss during incidents.
-
Prioritize Carbon-Intelligent Architectures: Sustainable Cloud Ops is no longer optional. Google’s Carbon-Intelligent Compute and AWS’s Graviton 4 chips exemplify how emission-aware designs reduce CO2 by 20% while improving cost efficiency—a dual imperative for ESG compliance and shareholder value.
5.2. The path forward: from operational necessity to strategic advantage
As David Linthicum notes, the cloud’s dynamic nature demands continuous adaptation. Organizations that relegate Cloud Ops to a support function risk operational diffusion—evidenced by LogicMelon’s pre-migration outages and CGA Strategy’s unpatched systems. Conversely, enterprises embracing Cloud Ops as a C-suite priority unlock transformative outcomes:
-
45% faster innovation cycles through AI-optimized CI/CD pipelines
-
60% lower breach risks via Zero Trust Architectures and automated threat hunting
-
30% higher employee retention when XLAs align IT performance with workflow efficiency
The future belongs to businesses that treat Cloud Ops not as a cost center but as an innovation engine. By institutionalizing the methodologies, trends, and case studies explored here, organizations will transcend mere resilience—they will pioneer the next frontier of digital competition, where cloud agility becomes synonymous with market leadership.
In an era where 92% of enterprises meet SLAs but only 34% achieve user satisfaction, Cloud Ops is the bridge between technical execution and business triumph. The question is no longer if to adopt these practices, but how swiftly and comprehensively to deploy them.
You are welcome to add any Comments and Feedback or reach out to me in private, via email for any follow-up thoughts!
Until the next one… Cheers,
